performance deviation between "float" and "double"
latency and throughput of MAD operation
reduction example in SDK 2.3 has a document, reduction.pdf
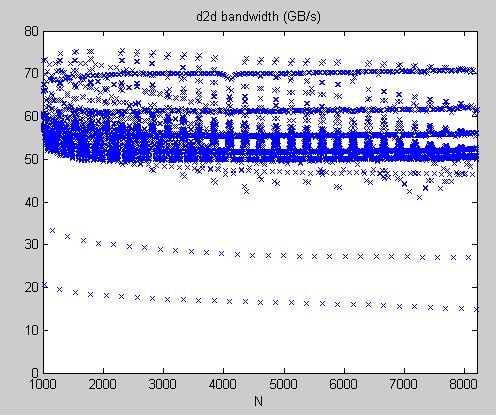
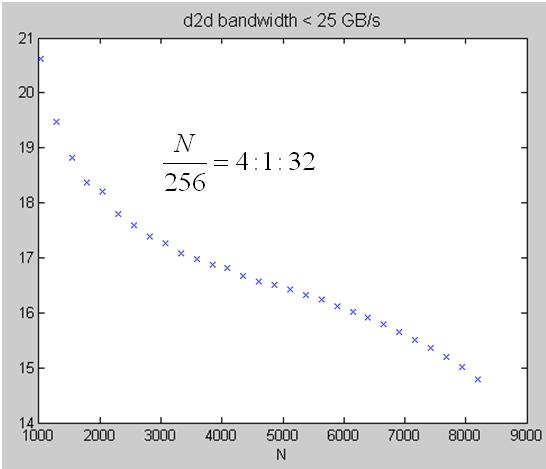
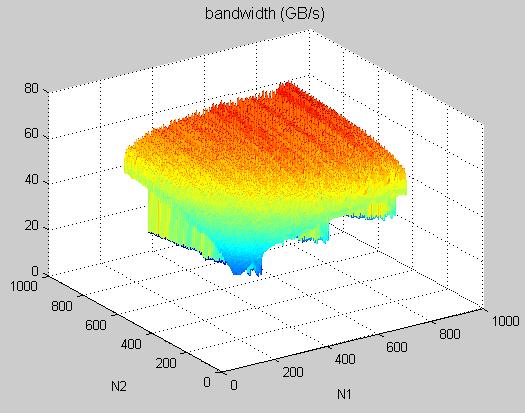
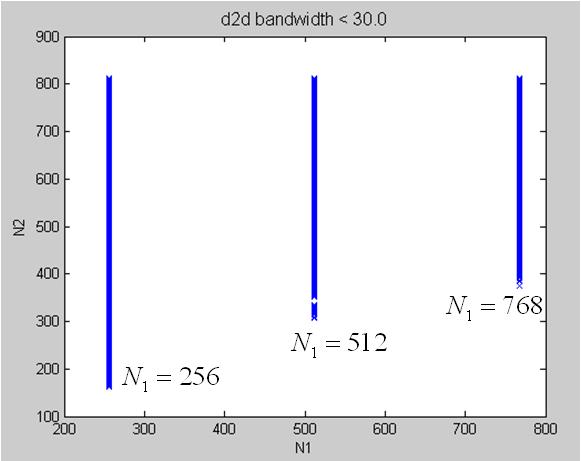
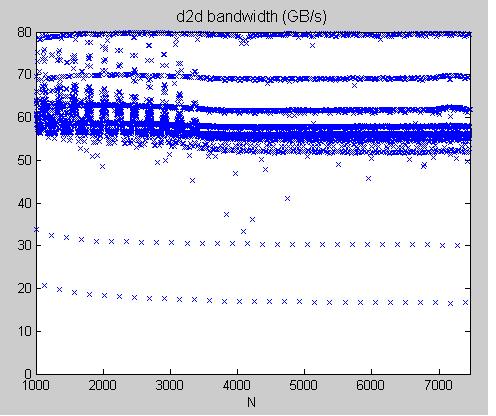
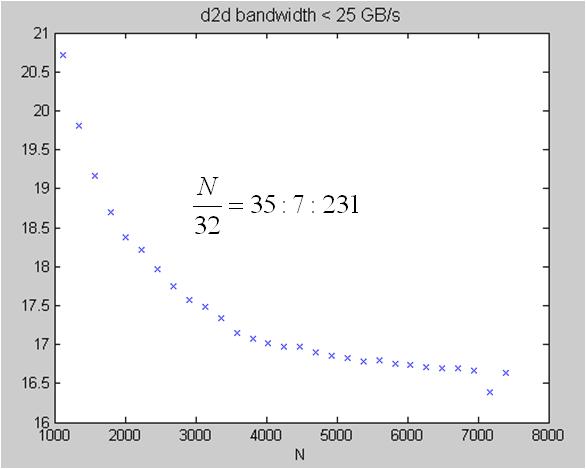
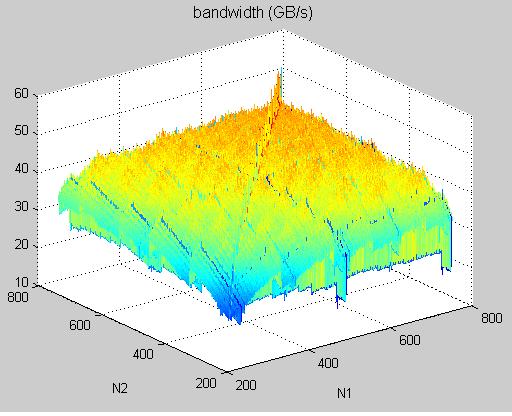
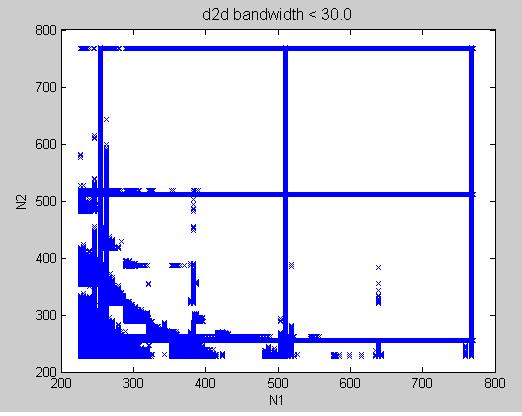
experimental result: coalesced transpose, proposed in SDK/transpose, on Tesla C1060
1. sweep over dimension n1 = n2, TeslaC1060_coalescedTranspose.jpg and
2. extract data set with bandwidth < 25 GB/s, TeslaC1060_coalescedTranspose_lowSpeed.jpg
3. sweep over dimension n1 ~= n2, TeslaC1060_coalescedTranspose_n1n2.jpg and TeslaC1060_coalescedTranspose_n1n2_lowSpeed.jpg
experimental result: coalesced transpose, proposed in SDK/transpose, on GTX295
1. sweep over dimension n1 = n2, GTX295_coalescedTranspose.jpg and GTX295_coalescedTranspose_lowSpeed.jpg
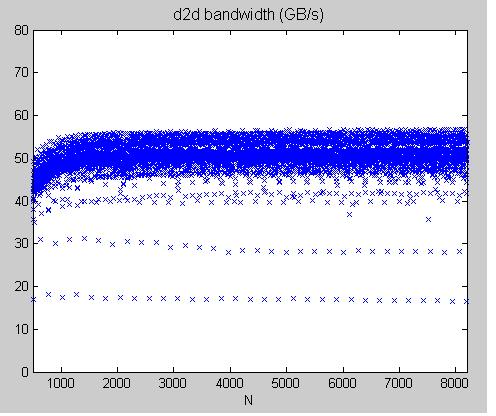
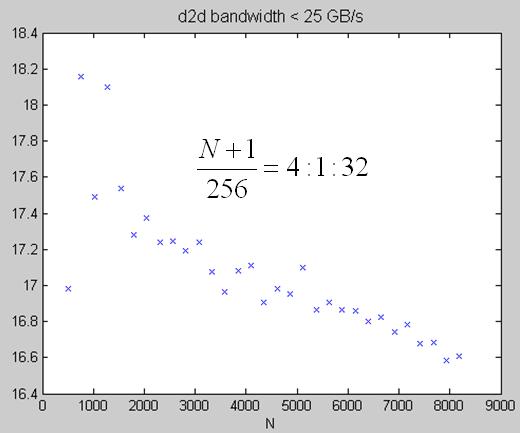
experimental result: diagonal transpose, proposed in SDK/transposeNew, on Tesla C1060
1. sweep over dimension n1 = n2, TeslaC1060_diagonalTranspose.jpg and TeslaC1060_diagonalTranspose_lowSpeed.jpg
2. sweep over dimension n1 ~= n2, TeslaC1060_transposeDiagonal_n1n2.jpg and TeslaC1060_transposeDiagonal_n1n2_lowSpeed.jpg
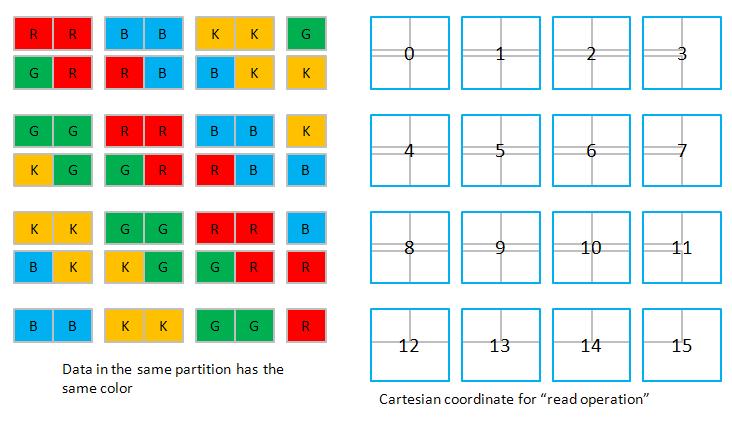
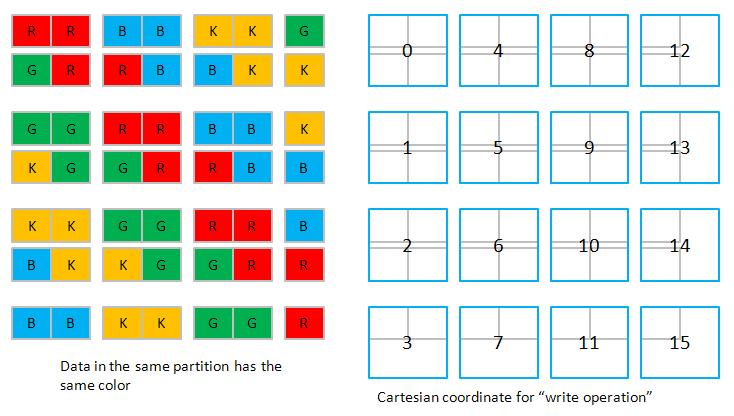
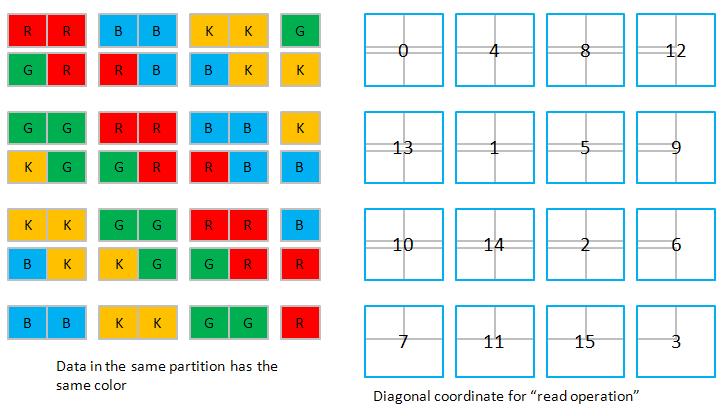
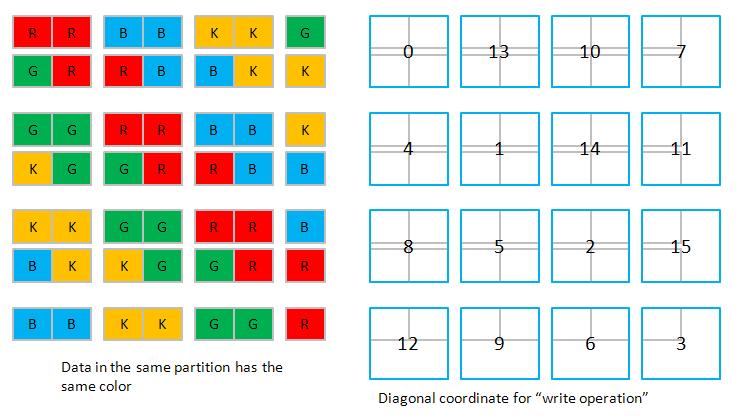
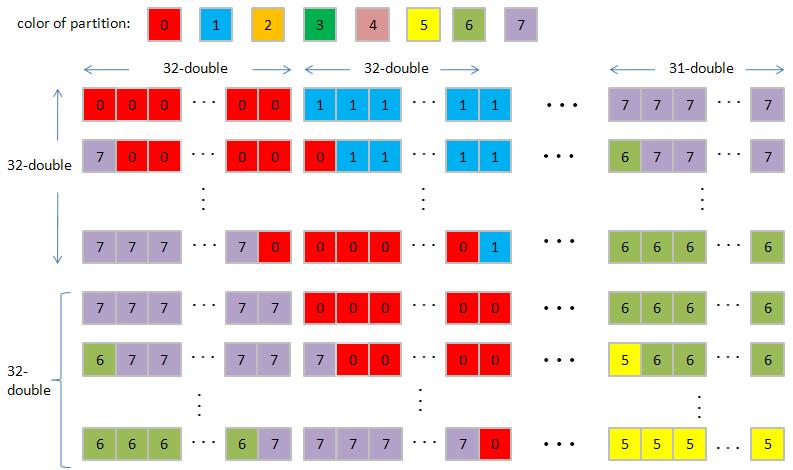
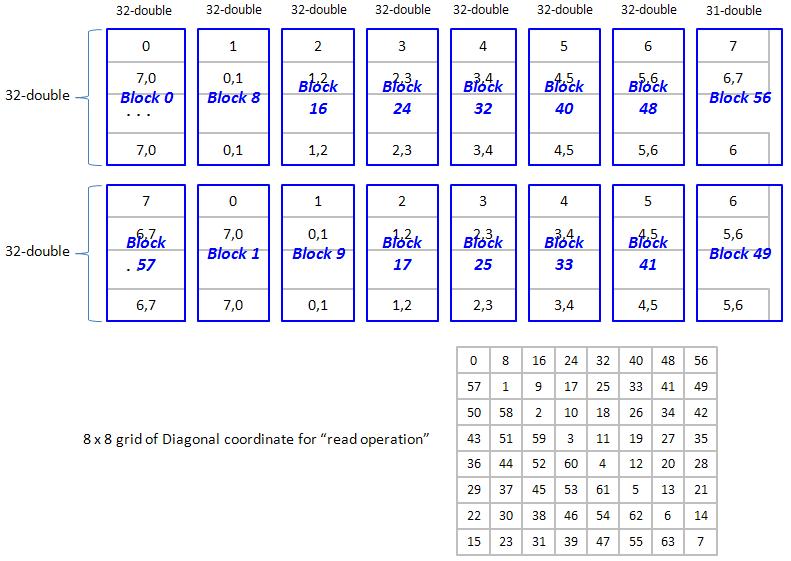
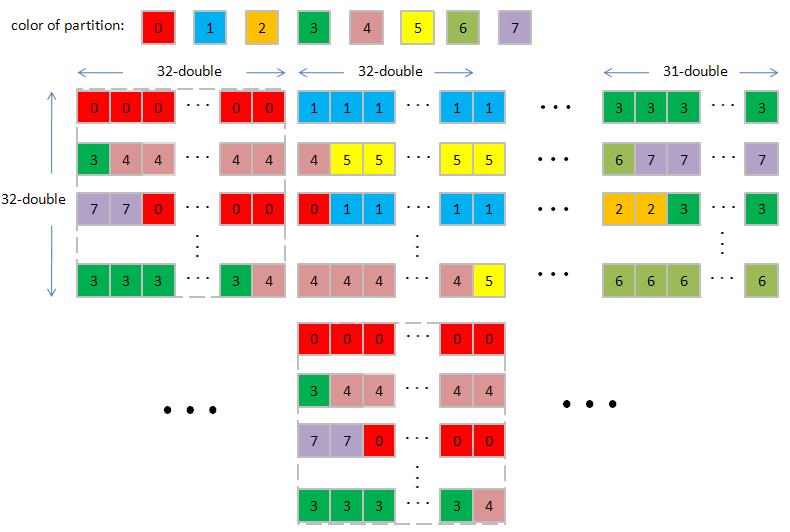
3. We use Tesla C1060 which has 8 partitions of 256-byte width (or say 32 doubles width), so all data in strides of 8 x 32 = 256 doubles map into the same partition. In order to simplify discussion, let us assume 4 partitions of 2-double width, then all data in strides of 4 x 2 = 8 doubles map into the same partition. Here we choose N = 7 and TILE_DIM = 2.
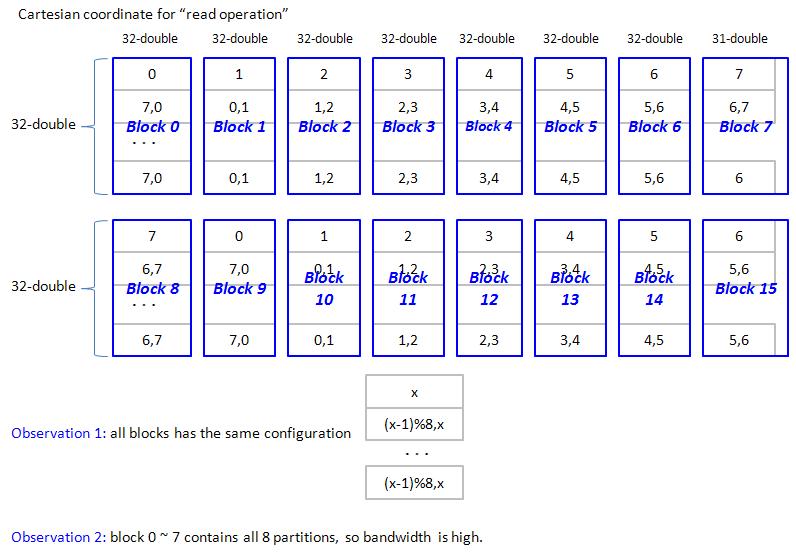
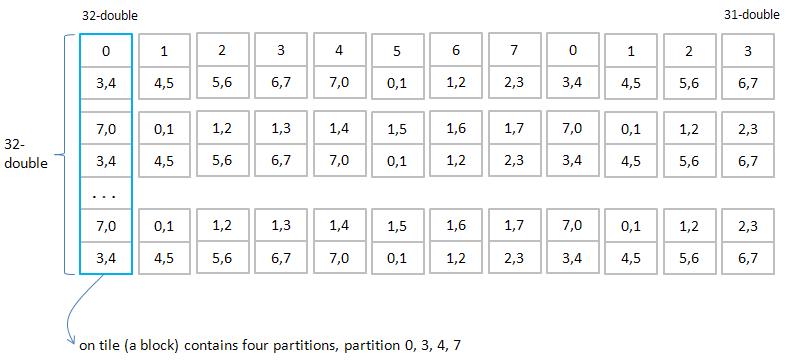
3.1 Cartesian read
3.2 Cartesian write
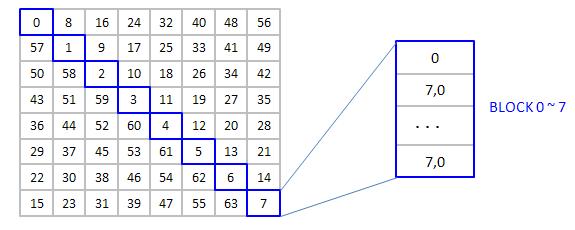
3.3 Diagonal read
3.4 Diagonal write
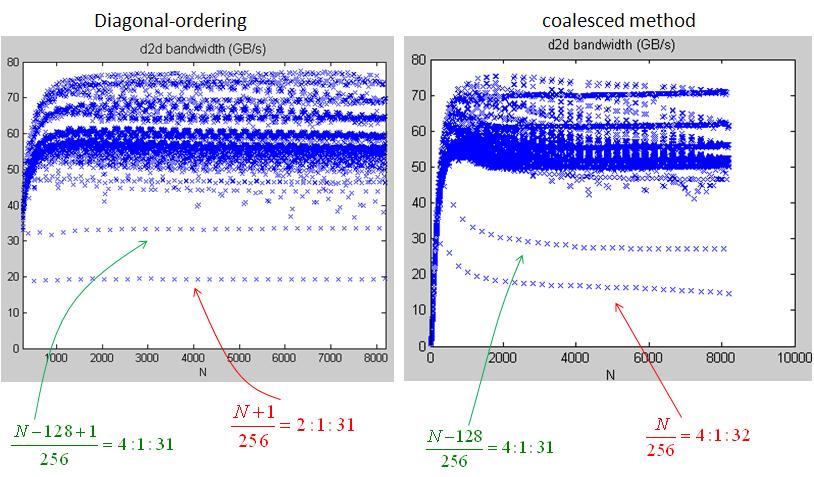
4.1 compare "diagonal-ordering" and "coalesced" on 2-D data set TeslaC1060_DiagOrder_Coalesced.jpg
4.2 compare "diagonal-ordering" and "coalesced" on 3-D data set Diagonal_vs_Coalesced_3D.jpg
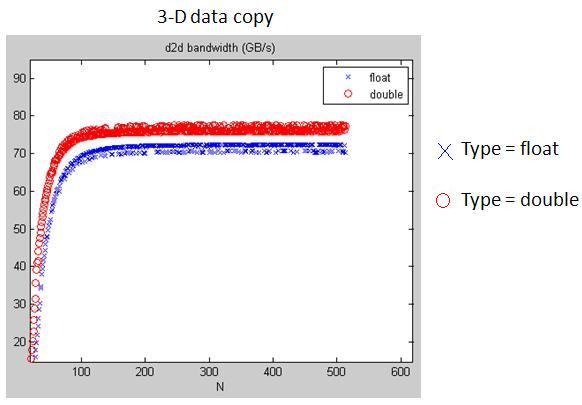
compare "float" and "double" on 3-D data copy, copy3D_float_vs_double.jpg
compare "float" and "double" on 3-D data transpose, transpose3D_float_vs_double.jpg
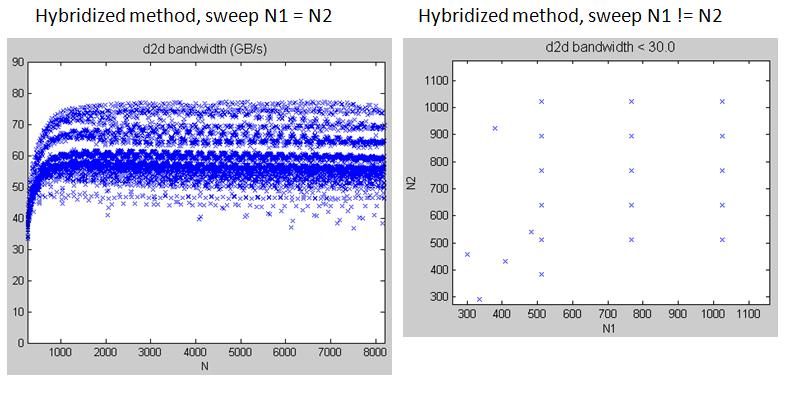
5. hybridized method combining "Coalesced" and "diagonal-ordering + fixedpoint + loop-unrolling" TeslaC1060_hybrid.jpg
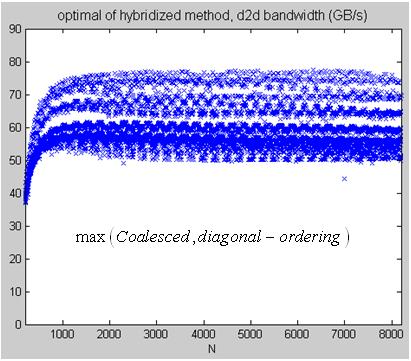
6. optimal of hybridized method, TeslaC1060_hybrid_optimal.jpg
7. show diagonal-ordering or N=255, diagonal_n255_1.jpg , diagonal_n255_2.jpg , diagonal_n255_3.jpg ,
diagonal_n255_4.jpg and diagonal_n255_5.jpg
8. show diagonal-ordering for N = 256 + 127, diagonal_n383_1.jpg , diagonal_n383_2.jpg and diagonal_n383_3.jpg
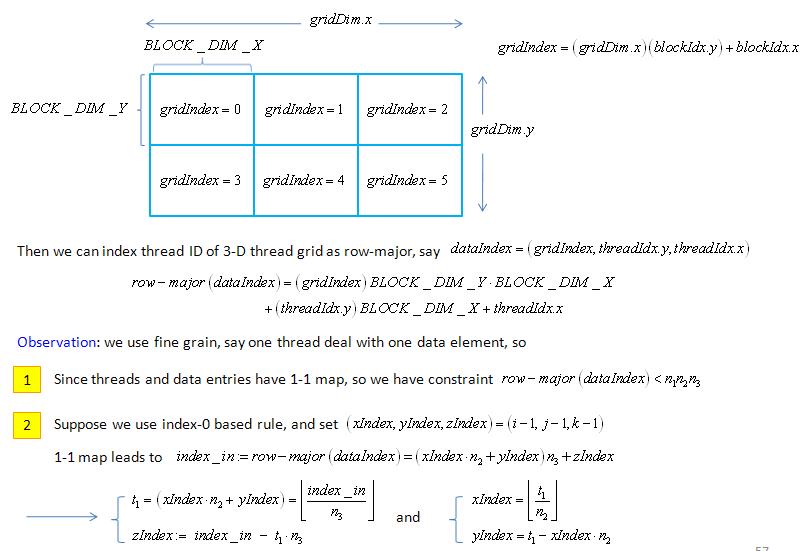
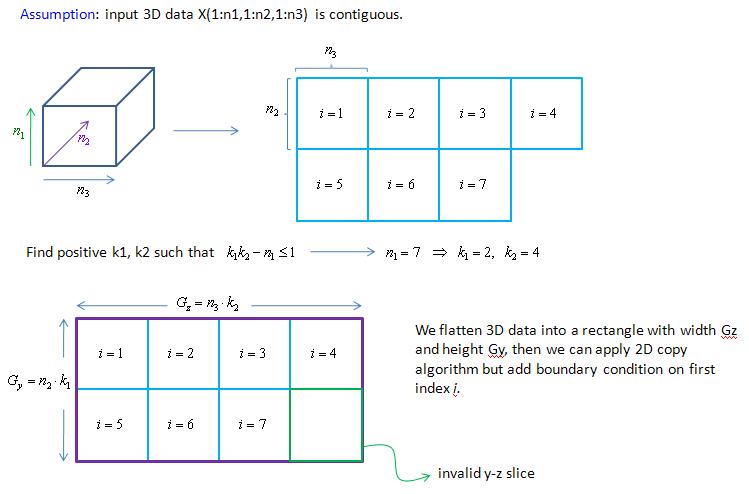
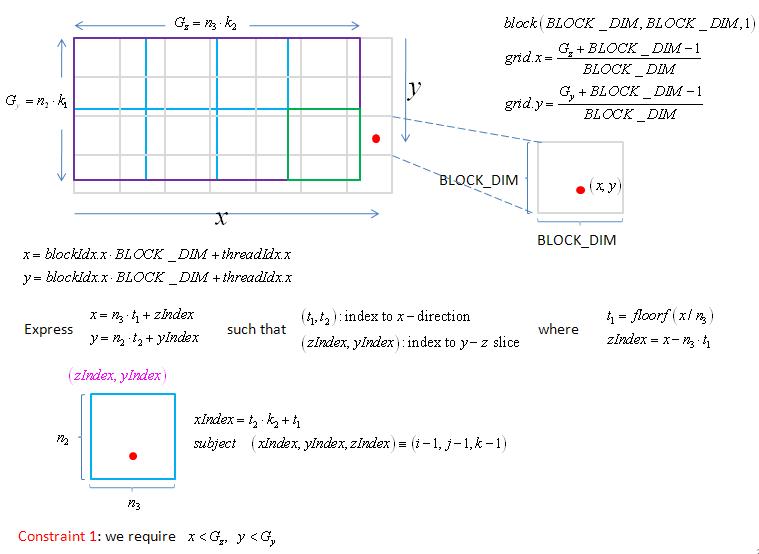
experiment: copy 3-D data, here we provide two index maps
1. naive map: map_1.jpg and map_2.jpg
2. typical map: map_1.jpg, map_2.jpg and map_3.jpg
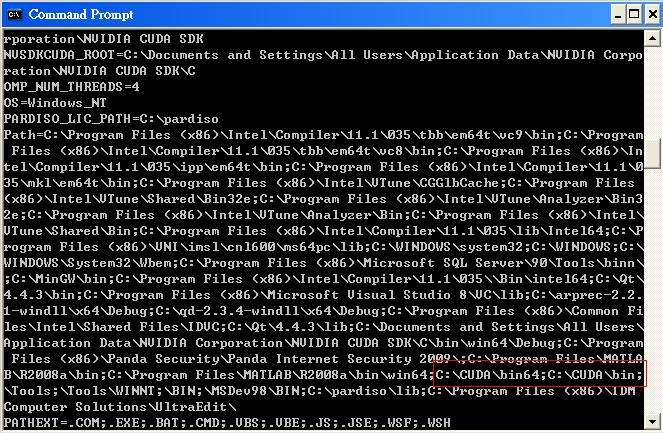
Question: Cross compiling in Vista 64 with CUDA 64, almost got it?
ans: require to setup correct path to 32-bit cudart.dll, environment.jpg and path_var.jpg
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}