I would like to report our SGEMM routine on GT200 GPUs. This work inherits Volkov's code, which can be downloaded from
http://forums.nvidia.com/index.php?showtopic=89084
Figure 1 shows performance (Gflop/s) of our method on TeslaC1060, GTX285 and GTX295. The baseline is Volkov's code on TeslaC1060 (black dash line).
Core frequency of GTX285 is 1.135x than that of TeslaC1060, and it is reasonable that performance of GTX285 is 1.165x than that of TeslaC1060.
Maximum performance of our method on TeslaC1060 in Figure is 439.467Gflop/s, this number achieves 70% of peak performance without dual issue
(peak performance of single precision without dual issue on TeslaC1060 is 624 Gflop/s) whereas Volkov's code reaches 346 Gflop/s, which is 55.45% of peak performance.
figure 1: comparison between our method and Volkov's code
[img]http://oz.nthu.edu.tw/~d947207/NVIDIA/SGEMM/figure1.JPG[/img]
source code can be downloaded from
http://oz.nthu.edu.tw/~d947207/NVIDIA/SGEMM/lsc_sgemm.zip
technical report: http://oz.nthu.edu.tw/~d947207/NVIDIA/SGEMM/HandTunedSgemm_2010_v1.1.pdf
source code: http://oz.nthu.edu.tw/~d947207/NVIDIA/SGEMM/lsc_sgemm.zip
Question: How about using __synchthreads() after "b_reg = b_ptr[j]" ?
I try your suggestion, case 2, into my algorithm, method 1, as following
[code]
b_ptr = (float*)b ;
#pragma unroll
for( int i = 0; i < BLOCK_SIZE_X; i++ ){
float A0_reg = A[0] ; A += lda ;
float A1_reg = A1[0] ; A1 += lda ;
// fetch b[i][:] into register b_reg[:]
#pragma unroll
for( int j = 0 ; j < BLOCK_SIZE_Y ; j++){
b_reg = b_ptr[j] ;
__syncthreads();
c0[j] += A0_reg * b_reg ;
c1[j] += A1_reg * b_reg ;
}
[code]
However nvcc reports error message as
[code]
tmpxft_00000bb8_00000000-3_method1_thread.cudafe1.gpu
tmpxft_00000bb8_00000000-8_method1_thread.cudafe2.gpu
nvopencc ERROR: C:\CUDA\bin64/../open64/lib//be.exe returned non-zero status -10
73741819
[/code]
I disable fully loop-unrolling of outer loop and change outer loop to #pragma
unroll 8
(BLOCK_SIZE_X = 16, BLOCK_SIZE_Y = 16). Also I use compiler option "-maxrregcount
48",
such that number of active thread = 320 (register count per thread = 46 ),
the same as method1_variant in report.
The code is called method1(synch)
[code]
b_ptr = (float*)b ;
#pragma unroll 8
for( int i = 0; i < BLOCK_SIZE_X; i++ ){
float A0_reg = A[0] ; A += lda ;
float A1_reg = A1[0] ; A1 += lda ;
// fetch b[i][:] into register b_reg[:]
#pragma unroll
for( int j = 0 ; j < BLOCK_SIZE_Y ; j++){
b_reg = b_ptr[j] ;
__syncthreads();
c0[j] += A0_reg * b_reg ;
c1[j] += A1_reg * b_reg ;
}
[code]
I indeed obtain "shared memory ---> register " from result of decuda.
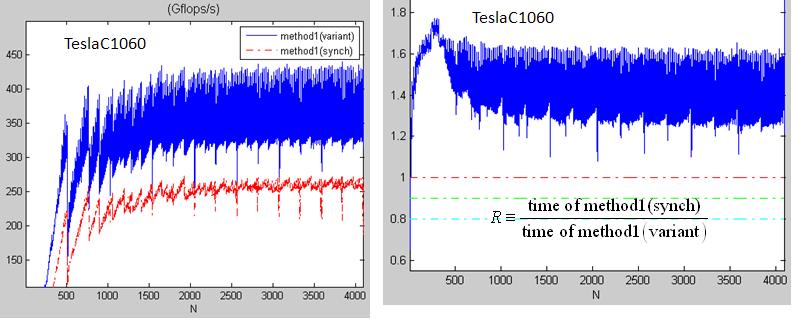
However the performance in figure 2 is not good, only 250Gflop/s.
I think that this is because of too many __syncthreads().
figrue 2: performance comparison between
method1(variant) and method1(synch)
method1(synch) only reaches 250Gflop/s, 30% slower than method1(variant).
In order to achieve high performance, we need to remove extra __synch
operations.
However we must reset offset of jump instruction after removing extra __synch
operations.
Besides, there is one thing strange. if I unroll inner loop explicitly, then
nvcc would remove extra __synch automatically, I don't know why.
{kind=link}
{kind=link}