global memory latency
in the thread http://forums.nvidia.com/index.php?showtopic=109558&pid=603432&mode=threaded&start=#entry603432
@Sylvain Collange said that
DRAM read cycle
is only a very small part of the total latency. It includes:
(1) Virtual address calculation. I suspect that even global memory reads have to
take the same path as texture reads, instead of a shortcut.
(2) On-chip crossbar interconnect traversal.
(3) Virtual to physical address translation.
(4) Physical to raw address translation (includes a division/modulo to
accommodate non-power-of-two numbers of partitions).
(5) Reordering from a deep buffer. Memory controllers aggressively reorder
accesses to minimize DRAM page switching and read/write turnaround overheads,
trading latency for throughput.
(6) The DRAM read cycle itself.
(7) Going back through the interconnect.
(8) Going through texture filtering units, if there is no shortcut datapath.
Thanks for @Sylvain Collange's comment, I have one question and several observations.
Question: in the thread http://forums.nvidia.com/index.php?showtopic=80451
@Sylvain Collange reports
[code]
On a 9800GX2,
when varying the data size, keeping a stride of 4K :
- from 4K to 64K : 320 ns
- from 128K to 8MB : 350 ns
- 16MB and more : 500 ns
[/code]
However I obtain 500 cycles latency under stride is 4K in TeslaC1060
when using cuda_latency.tar.gz provided by @Sylvain Collange in the thread
http://forums.nvidia.com/index.php?showtopic=80451&pid=468968&mode=threaded&start=#entry468968
Table 1: keep stride = 4KB and sweep data size from 4KB to 64MB, then latency is about 500 core cycle.
[code]
%
stream_test( void ) : Stream reads
% use device 2, name = Tesla C1060
% data_size_min = 4.00 kB
% stride_min = 4096 byte
% data_size_max = 77056.00 kB
% stride_max = 4096 byte
% runs stride size(kB) clocks ns
5 4096 4.00
506 409.40
5 4096 8.00
508 411.02
5 4096 16.00
506 409.40
5 4096 32.00
506 409.40
5 4096 64.00
506 409.40
5 4096 128.0
506 409.40
5 4096 256.0
504 407.78
5 4096 512.0
506 409.40
5 4096 1024.0
506 409.40
5 4096 2048.0
506 409.40
5 4096 4096.0
498 402.93
5 4096 8192.0
506 409.40
5 4096 16384.0
504 407.78
5 4096 32768.0
504 407.78
5 4096 65536.0
504 407.78
[/code]
Do I miss something so that latency is about 500 cycles?
Observation: what I am concerned is throughput, when I use Gatt chart to analyze bandwidth difference between "float" and "double",
I am confused that how to embed idea of "partition camping" into Gatt chart. In other words, I want to ask
Is
memory interface also divided into 7 or 8 partitions? say
GTX295 has 448-bit per GPU, 448 = 64 * 7, each partition uses 64-bit interface.
TeslaC1060 has 512-bit interface, 512 = 64*8, each partition uses 64-bit
interface.
I think that this question is answered in the thread http://forums.nvidia.com/index.php?showtopic=80451&pid=457188&mode=threaded&start=#entry457188
@alex dubinsky said
"Btw, there is an alternate explanation for variable latencies. The DRAM is organized into channels, and depending on how you access the channels (for example, sending all accesses to one or spreading them out) will affect performance by a large amount. "
I think that "channel" is "partition" mentioned in SDK/transposeNew/doc/MatrixTranspose.pdf.
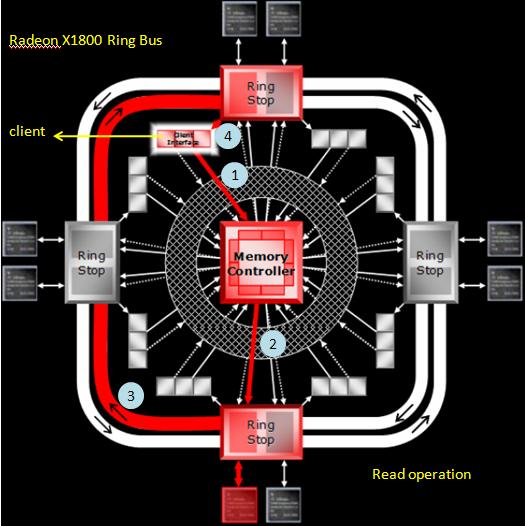
I search "channel GDDR3" on google, then it appears in the SPEC of ATI product, in the white paper of Radeon X1800,
http://ati.amd.com/products/radeonx1k/whitepapers/X1800_Memory_Controller_Whitepaper.pdf, it shows
(1) The Radeon X1800 Memory Controller takes advantage of this fact by dividing its 256-bit memory interface into eight 32-bit channels, see figure 1
A key issue with moving to a wider memory interface relates to the concept of granularity. For maximum efficiency, every wire in the interface should ideally be carrying data every clock cycle. for example, if a request for 32 bits of data was made on a 256-bit interface, it could mean that most of the wires would not be carrying any data when the request was fulfilled.
GPUs typically address this granularity issue by dividing their memory interfaces into multiple channels. Each channel can serve one read or write request at a time, so an interface with multiple channels can serve multiple requests simultaneously.
(2) Ring Bus architecture of Radeon X1800, see figure 2
figure 1, Radeon X1800_1.jpg
[img]http://oz.nthu.edu.tw/~d947207/NVIDIA/gmem_latency/Radeon_X1800_1.JPG[/img]
figure 2, Radeon X1800_2.jpg
[img]http://oz.nthu.edu.tw/~d947207/NVIDIA/gmem_latency/Radeon_X1800_2.JPG[/img]
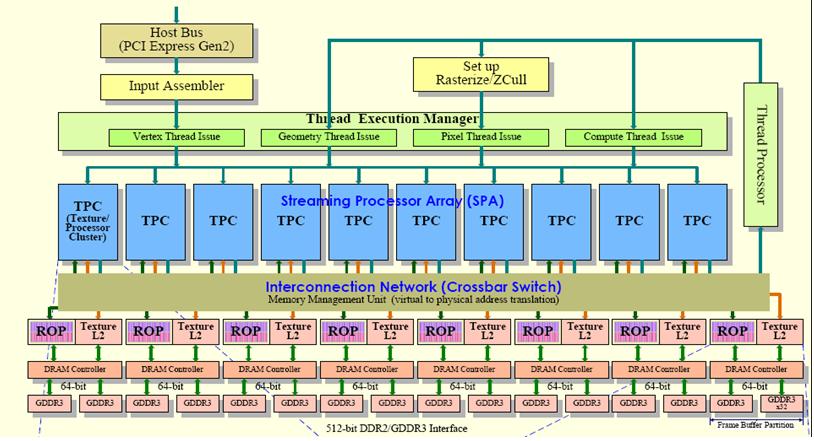
also from http://pc.watch.impress.co.jp/docs/2008/0617/kaigai446.htm by Hiroshige Goto (the link is provided by @Sylvain Collange),
an overview of GT200 is shown in figure 3, it shows that GT200 has 8 channels, 64-bit interface per channel and use 32-bit memory device,
for example, TeslaC1060 use 32 32Mx32 GDDR3 SDRAM.
figure 3, GT200.jpg
[img]http://oz.nthu.edu.tw/~d947207/NVIDIA/gmem_latency/GT200.JPG[/img]
Conclusion:
when one wants to improve performance of a memory-bound problem, like matrix transpose we have discussed in the thread
http://forums.nvidia.com/index.php?showtopic=106924 , the partition camping needs to be solved first (or concurrent accesses to global memory by all
active warps should be divided evenly amongst partitions (channels) ) since if all SMs access the same channel, then effective interface is 64-bit, not 512-bit,
then effective bandwidth is only 1/8 of maximum bandwidth, this is independent of how many cores you are using.
Of course, "each channel can only access 64-bit interface" means that my Gatt chart in the thread
http://forums.nvidia.com/index.php?showtopic=106924&pid=601970&mode=threaded&start=#entry601970
is wrong.
Moreover if latency is 500 cycles and "read cycle of DRAM" is only 110 cycles, then fixed cost of access DRAM is about 400 cycles
(fixed cost = Virtual address calculation + On-chip crossbar interconnect traversal + Virtual to physical address translation + Physical to raw address translation
+ Physical to raw address translation). This means that if one wants to draw Gatt chart, then he can ignore variation due to bank-conflict, or different rows of the same bank, ... etc.
{kind=link}
{kind=link}
{kind=link}