performance deviation between "float" and "double"
To discuss performance deviation of Read/Write among “float”, “double” and “float3”, it suffices to verify the behavior via data-copy.
We focus on device of compute capability 2.3, especially target on TeslaC1060.
So far, we can classify factors affecting bandwidth as two categories:
Category 1: Time-independent (programmer does not need to care about timing of commands)
(1) Coalesced pattern (discussed in programming Guide)
Coalescing into a single transaction can occur when data lies in 32-, 64-, and 128-byte aligned segments,
regardless of the access pattern by threads within the segment.
(2) Partition camping (discussed in SDK\transposeNew\doc\MatrixTranspose.pdf)
partition camping concerns global memory accesses amongst active half warps. Since partition camping concerns how active thread blocks behave,
the issue of how thread blocks are scheduled on multiprocessors is important.
( Definition: Partition camping is used to describe the case when global memory accesses are directed through a subset of partitions,
causing requests to queue up at some partitions while other partitions go unused. )
Category 2: Time-dependent
(3) Execution order of index computation and global Read/Write operation
This is tedious that one should draw Gatt chart to depict the timing sequence
(4) Behavior of GDDR3
Most programmers only care about category 1, one can organize access pattern to achieve coalesced property and interpret logical index of block ID
to avoid partition camping. Sometimes programmers design a scheme for generic data type, and re-define this data type to either "float" or "double".
code looks like
[code]
typedef float data_type ; // data_type = float or double
__global__ scheme( data_type a )
{
....
}
[/code]
This is reasonable from Top-Down design, however this may not be good, even coalesced pattern can be kept, you may suffer partition camping.
We will give a simple data-copy example to show partition camping in PART I. Second we use generic SDRAM model in [1] to model GDDR3 and
review some Gatt chart of DRAM behavior under complete read-cycle and consecutive reads in PART II. Finally in PART III, we design an example "blockEqPartition"
which ensures that width of tile is the same as width of partition, then we can explain why bandwidth of "double" is larger than bandwidth of "float".
[1] Bruce Jacob, Spencer W. Ng, David T. Wang, MEMORY SYSTEMS Cache, DRAM, Disk
Part I: Coalesced pattern and partition camping
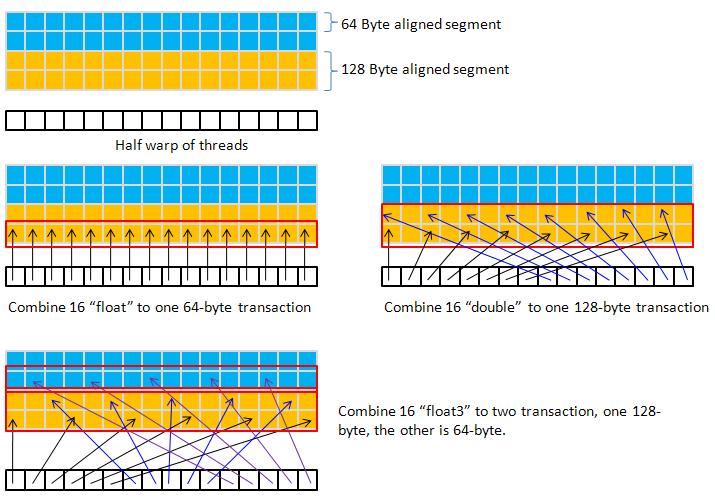
in programming guide, we know that simultaneous memory accesses by threads in a half-warp (during the execution of a single read or write instruction)
can be coalesced into a single memory transaction of 32 bytes, 64 bytes (16 floats), or 128 bytes (16 doubles) .
in this report, what we are concerned is 16-float, 16-double and 16-float3 of half-warp, the pattern is shown in figure 1.
16-float and 16-double can be merged into one transaction respectively where 16-float requires two transactions.
It is easy to keep "float", "double" and "float3" as coalesced pattern in data-copy problem.
Hence partition camping is the only factor we should take care in category I.
figure 1: coalesced_pattern.jpg
from programming guide 2.3 and /SDK/transposeNew/doc/MatrixTranspose.pdf (SDK 2.3), we know
1. global memory is divided into either 7 partitions (GTX260, GTX295) or 8 partitions (TeslaC1060) of 256-byte width.
2. Allocating device memory through cudaMalloc() alignment with a segment of memory.
3. To use global memory effectively, concurrent accesses to global memory by all active warps should be divided evenly amongst partitions.
(this can avoid partition camping)
to show partition camping, we take a simple example "coalesced copy" which comes from /SDK/transposeNew
here is C-wrapper
[code]
#define TILE_DIM 32
#define BLOCK_ROWS 8
void copy2D_Coalesced_device( doublereal *odata, doublereal *idata, int n1, int n2)
{
dim3 threads(TILE_DIM, BLOCK_ROWS, 1);
dim3 grid( (n2 + TILE_DIM-1) / TILE_DIM, (n1 + TILE_DIM-1) / TILE_DIM, 1);
copy2D_Coalesced<<< grid, threads >>>( odata, idata, n2, n1 ) ;
}
[/code]
and its kernel function
[code]
static __global__ void copy2D_Coalesced(doublereal *odata, doublereal* idata, int width, int height )
{
int xIndex = blockIdx.x * TILE_DIM + threadIdx.x;
int yIndex = blockIdx.y * TILE_DIM + threadIdx.y;
int index = xIndex + width*yIndex;
for (int i=0; i<TILE_DIM; i+=BLOCK_ROWS) {
odata[index+i*width] = idata[index+i*width];
}
}
[/code]
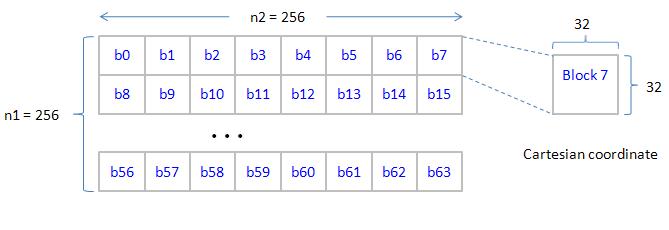
Consider n1 = n2 = 256, one threads block (256 threads) deals with a tile = 32 x 32 elements, so we have 64 blocks.
we adopt Cartesian coordinate to index a tile, ID of tiles are shown in figure 2
figure 2, copy2D_coalesced_p1.jpg
note that generic type "doublereal " can be "float", "double" or "float3" such that execution configuration of “float”, “double” and ”float3” are the same,
and R/W of “float”, “double” and ”float3” are coalesced pattern.
However performance among them can be quite different due to partition camping. Next we need to analyze effect of partition camping.
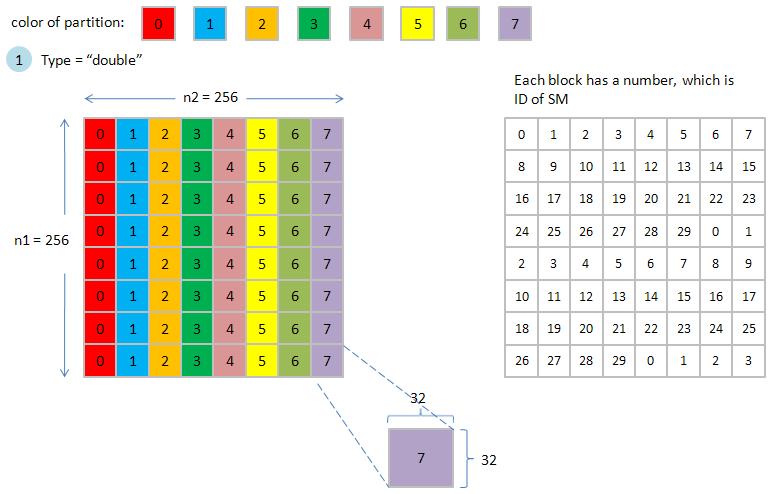
Next we label each tile with one color to show its partition, in figure 3, a tile of type "double" occupies a partition, under Cartesian coordinate ordering, all 8 partitions are activated simultaneously. This is the best way that we can expect.
figure 3, copy2D_coalesced_p2.jpg
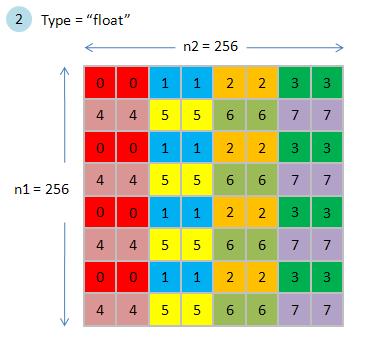
in figure 4, two tiles of type "float" occupy a partition, if number of active blocks exceeds 16, then we also expect that all partitions can be active
at the same time. Under consideration of partition camping, we cannot distinguish performance between "float" and "double".
figure 4, copy2D_coalesced_p3.jpg
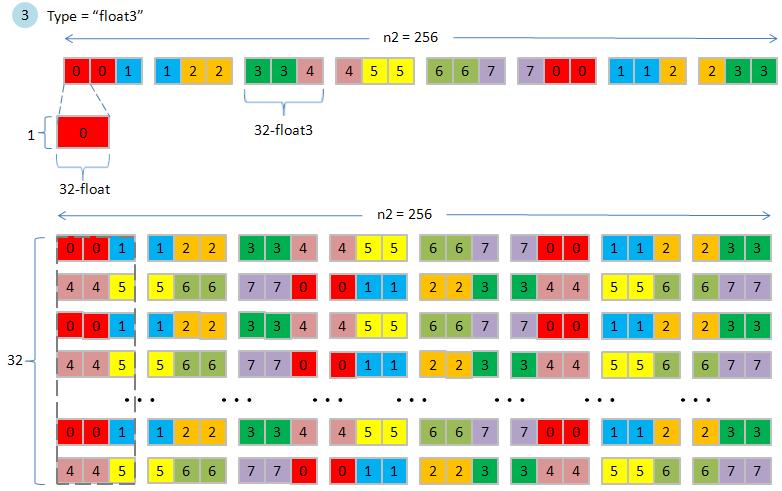
in figure 5, we use 32-float as basic color rectangle since one row of a tile is 32-float3 which is 32x3x4 = 378 byte, this exceeds width of a partition (256 bytes).
two tiles of type "float3" occupy two partitions, this increase degree of difficulty to analyze its effect of partition camping.
some partitions across two blocks,
figure 5, copy2D_coalesced_p4.jpg
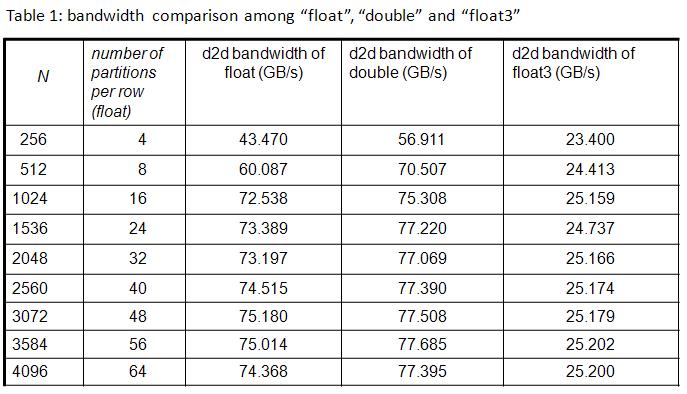
The result of experiment on TeslaC1060 is show in table 1. It is clear that bandwidth of "float" is slightly smaller than bandwidth of "double",
however bandwidth of "float3" is dramatically worse than "float". I believe that this is because partition camping, but I cannot show you evidence.
table 1, copy2D_coalesced_p5.jpg
from result of example "coalesced copy", if we want to discuss "why transfer of double is faster a little bit than transfer of float", then it is reasonable to align boundary of a tile to boundary of a partition.
PART II: behavior of GDDR3
from http://en.wikipedia.org/wiki/GDDR3, it says
"GDDR3 has much the same technological base as DDR2, but the power and heat dispersal requirements have been reduced somewhat, allowing for higher performance memory modules, and simplified cooling systems. To improve bandwidth, GDDR3 memory transfers 4 bits of data per pin in 2 clock cycles."
hence in this report, we use DDR2 to model GDDR3.
Here I adopt description of generic SDRAM device in book "MEMORY SYSTEMS Cache, DRAM, Disk".
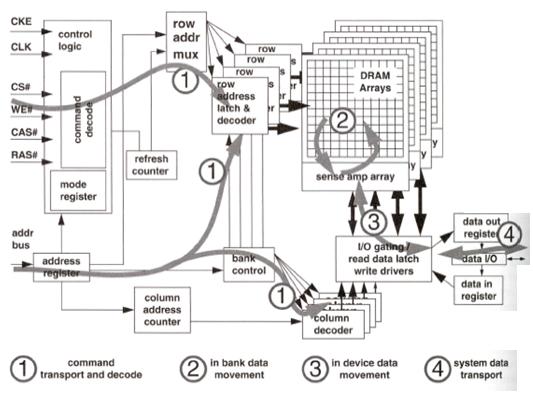
in figure 6, memory device (a memory chip) is divided into four parts with different functions such that we can have four-stage pipeline in DRAM
figure 6, DDR_p1.jpg
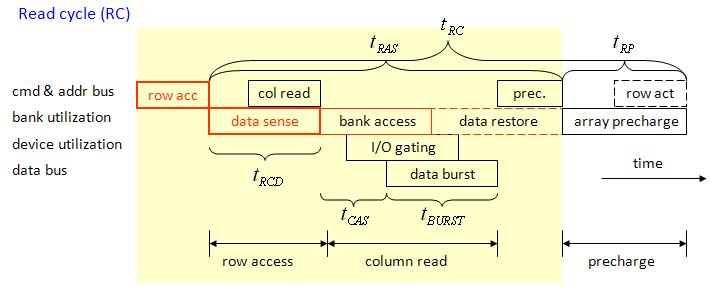
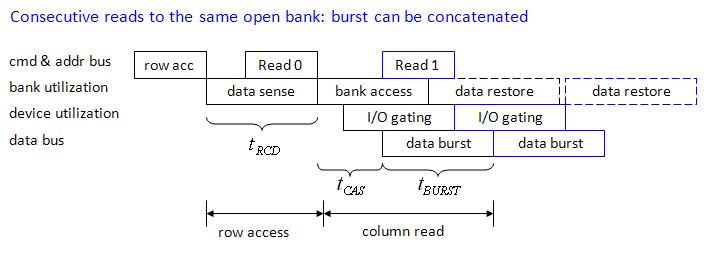
Gatt chart of a complete ready cycle is shown in figure 7, it relates to row access, column read, data restore and pre-charge.
figure 7, DDR_p2.jpg
consecutive reads is shown in figure 8, burst length of SDRAM is 4 or 8, in order to transfer large data chunk, for example,
64-byte (16-float) or 128-byte (16-double), we need multiple consecutive reads, and data burst can be concatenated.
This means that we can transfer 64-byte or 128-byte in a contiguous manner (hide CAS latency).
figure 8, DDR_p3.jpg
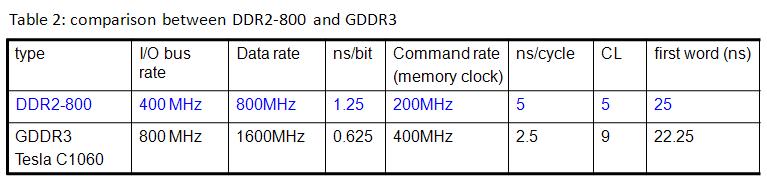
So far, we will regard GDDR3 as DDR2. Memory clock in TeslaC1060 is 800MHz, I think that it is I/O bus rate, and data rate is 1600MHz due to "double data rate".
under spec of DDR2, we write down some parameters of GDDR3 in table 2.
table 2, DDR_p4.jpg
from thesis of Wilson Wai Lun Fung (https://circle.ubc.ca/bitstream/2429/2268/1/ubc_2008_fall_fung_wilson_wai_lun.pdf ),
the author adopts GDDR3's timing parameters provided by Qimonda for their512-Mbit GDDR3 Graphics RAM clocked at 650MHz.
We adopt the same timing parameters except frequency (TeslaC1060 is 800MHz). The parameters are summarized in table 3.
table 3, DDR_p5.jpg
Let us estimate duration of a complete read cycle.
read cycle = tRC = tRAS + tRP= 21 + 13 = 34 (memory cycle)
core frequency of Tesla C1060 is 1.3GHz and memory clock is 400MHz, then
read cycle = 34 (memory clock) x 1.3GHz/400MHz = 110.5 (core cycle)
However from programming guide 5.1.1.3, it says “Throughput of memory operations is 8 operations per clock cycle.
When accessing local or global memory, there are, in addition, 400 to 600 clock cycles of memory latency.”
Two numbers, "110.5 cycles" and “400 to 600 clock cycle” are far from each other.
In this report, we set memory latency as 400 cycles.
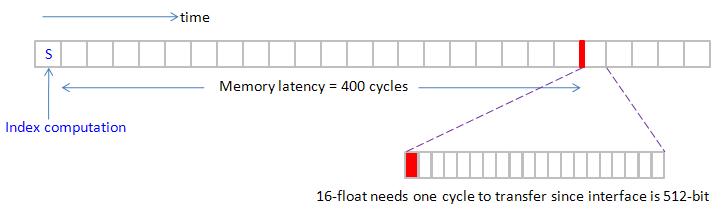
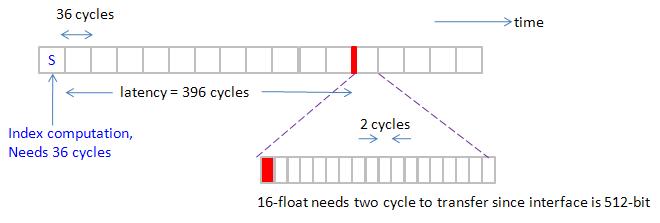
To sum up, memory interface is 512-bit in TeslaC1060, it can transfer 512-bit (or 64 bytes or 16 floats) in one cycle when data is in I/O buffer.
For coalesced pattern,
1. 16-“float” in one transaction requires 1 cycle to transfer data through bus
2. 16-“double” in one transaction require 2 cycles to transfer data through bus
3. 16-“float3” in two transaction require 3 cycles at least to transfer data through bus
PART III: boundary of a tile is aligned to boundary of a partition
From previous discussion, configuration of coalesced method is good for “double”, but not good for “float” and “float3”.
Rule of thumb: choose a thread block to deal with a tile with boundary aligned to a partition (width of a tile is equal to width of a partition).
Next we demo a another example, called "blockEqPartition", in which
1. it uses tile = 32 x 16 to deal with type = "double"
2. it uses tile = 64 x 8 to deal with type = "float"
Here we neglect type = "float3" since it is hard to match "width of a tile is equal to width of a partition"
C-wrapper of "blockEqPartition" is
[code]
#define NUM_PARTITION 1
#ifdef DO_DOUBLE
#define TILE_DIM_X 32
#define TILE_DIM_Y 16
#else
#define TILE_DIM_X 64
#define TILE_DIM_Y 8
#endif
void copy2D_blockEqPartition_device( doublereal *odata, doublereal *idata, int n1, int n2)
{
dim3 threads(TILE_DIM_X, TILE_DIM_Y, 1);
unsigned int k1 = (n1 + TILE_DIM_Y-1) / TILE_DIM_Y ;
unsigned int k2 = (n2 + TILE_DIM_X-1) / TILE_DIM_X ;
dim3 grid( NUM_PARTITION, 1, 1);
float eps = 1.0E-6 ;
float one_over_k2 = (1.0+eps)/((double)k2) ;
copy2D_blockEqPartition<<< grid, threads >>>( odata, idata, n2, n1, one_over_k2, k2, k1*k2 ) ;
}
[/code]
and its kernel is
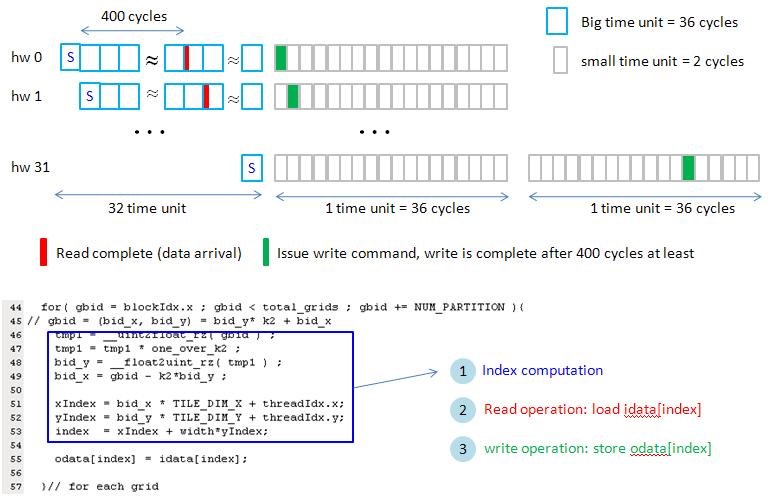
[code]
static __global__ void copy2D_blockEqPartition(doublereal *odata, doublereal* idata, int width, int height,
float one_over_k2, unsigned int k2, unsigned int total_grids )
{
unsigned int gbid, bid_x, bid_y , xIndex, yIndex, index ;
float tmp1 ;
for( gbid = blockIdx.x ; gbid < total_grids ; gbid += NUM_PARTITION ){
// gbid = (bid_x, bid_y) = bid_y* k2 + bid_x
tmp1 = __uint2float_rz( gbid ) ;
tmp1 = tmp1 * one_over_k2 ;
bid_y = __float2uint_rz( tmp1 ) ;
bid_x = gbid - k2*bid_y ;
xIndex = bid_x * TILE_DIM_X + threadIdx.x;
yIndex = bid_y * TILE_DIM_Y + threadIdx.y;
index = xIndex + width*yIndex;
odata[index] = idata[index];
}// for each grid
}
[/code]
We use parameter "NUM_PARTITION" to set how many SMs are used in the kernel.
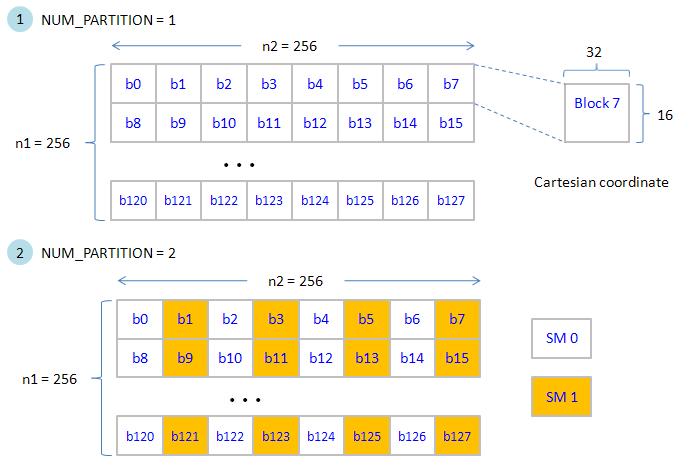
In upper panel of figure 9, a tile has dimension 32 x 16 (type is "double"), there are 8 x 16 = 128 tiles in 256x256 data, however only one thread block (32x16 threads) is invoked to deal with 128 tiles for NUM_PARTITION = 1. This means that only one SM works, remaining 29 SMs are idle.
here we adopt Cartesian coordinate ordering such that consecutive 8 blocks can activate 8 partitions simultaneously.
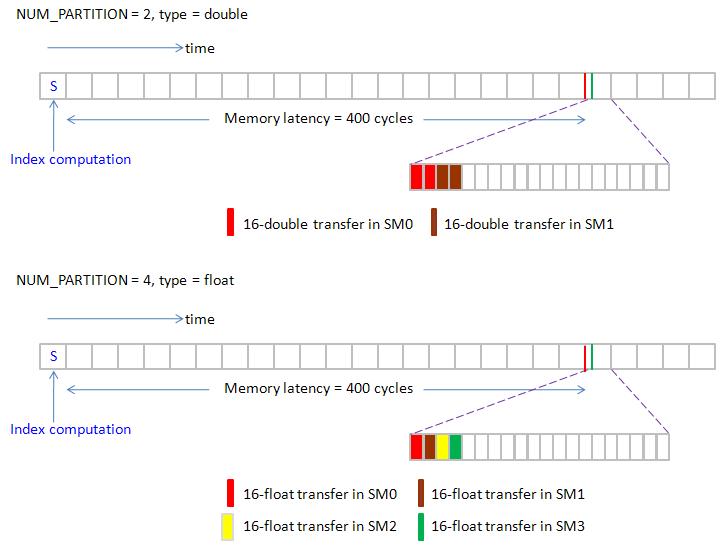
if NUM_PARTITION = 2, then two thread blocks are invoked to handle 128 tiles (say only two SMs do work ), execution order is shown in lower panel of figure 9.
figure 9, blockEqPartition_p1.jpg
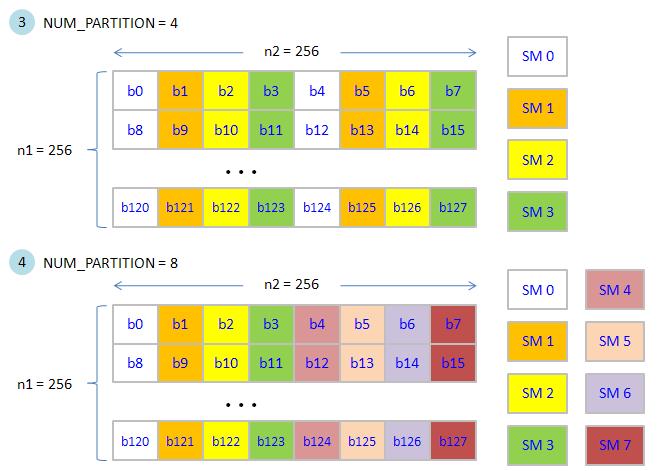
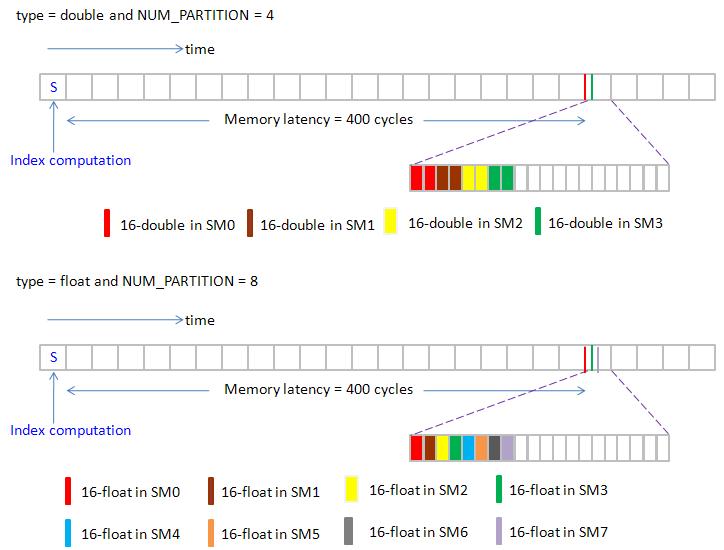
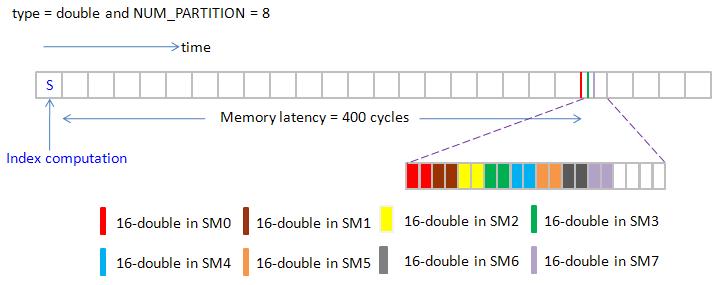
figure 10 shows execution order of NUM_PARTITION = 4 (4 SMs) and NUM_PARTITION = 8 (8 SMs)
note that for NUM_PARTITION = 8, we can activate 8 partitions simultaneously, this is the best we expect.
figure 10, blockEqPartition_p2.jpg
Comparison of bandwidth between "float" and "double" under different NUM_PARTITION is listed in table 4
Table 4, blockEqPartition_p3.jpg
from experimental result, bandwidth of "double" is two times the bandwidth of "float".
Next we want to use Gatt chart to explain this phenomenon.
first we introduce three assumptions in later discussion,
Assumption 1: index computation requires 20 cycles for “float” and “double”
in fact, cost of "index computation" is about 18.2 cycles, this number is estimated via Block-wise test harness
(http://forums.nvidia.com/index.php?showtopic=103046 ) provided by SPWorley.
In order to simplify discussion, we set it as 20 cycles.
(code of index computation is shown in figure 11)
figure 11, blockEqPartition_p4.jpg
Assumption 2: memory latency is 400 cycles but 16-float can be transferred at 401-th cycle, 16-double can be transferred at 402-th cycle.
Assumption 3: scheduler of SM uses round-robin to choose next half-warp from ready-queue. (this is not true since basic unit of scheduling is a warp, not half-warp. Why we schedule half-warp is just to simplify discussion)
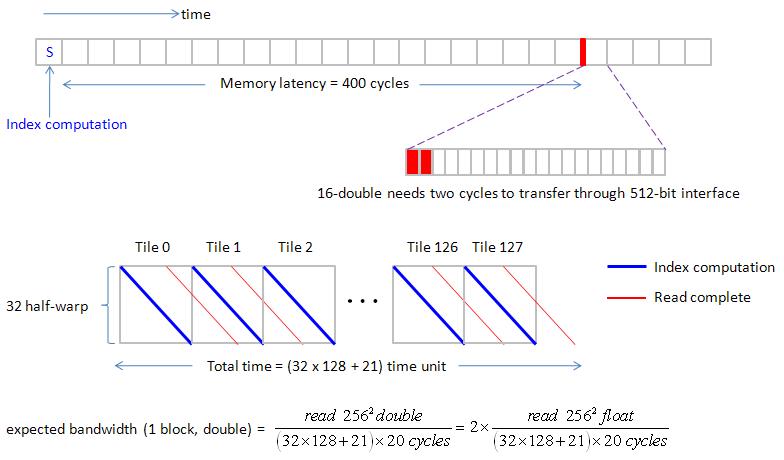
Case 1: type = float and NUM_PARTITION = 1, (only one SM executes 32 half-warp).
We use Gatt chart to describe execution order of all 32 half-warp (512 threads per block). The time unit is 20 cycles. For simplicity, we only consider read operation. In figure 12, SM executes "index computation" at first time unit and then issue read command, after 400 cycles, data is transferred from SDRAM to registers in one cycle.
figure 12, blockEqPartition_p5.jpg
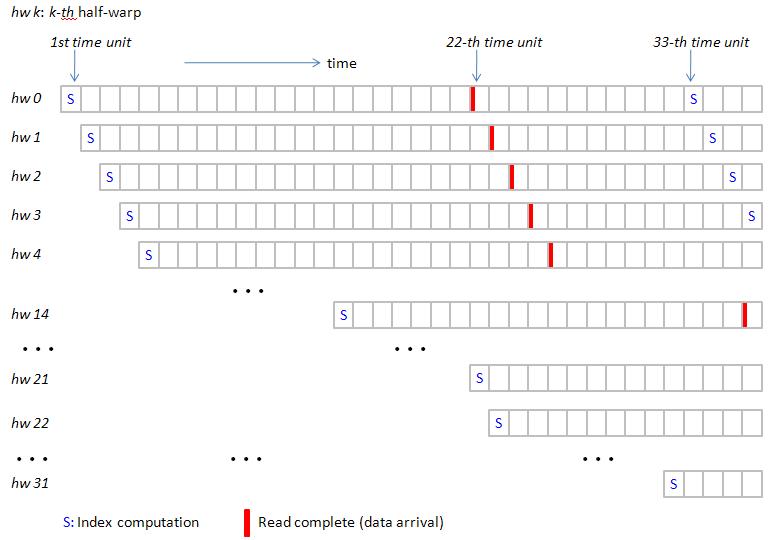
there are 32 half-warps but only one SM, so 32 half-warps must be executed in turn (we assume round-robin to schedule half-warps).
In figure 13, each half-warp has a time chart and we arrange time chart of half-warp in ascending order.
figure 13, blockEqPartition_p6.jpg
We set NUM_PARTITION = 1 to obtain figure 13, only one SM works, it has 512 active threads which are divided into 32 half-warp.
We label half-warp as hw0, hw1, hw2, …, hw31.
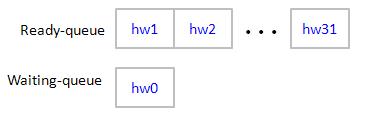
1st time unit: SM0 computes index of hw0, then does read operation. At this moment, hw0 goes to waiting-queue. Scheduler chooses hw1 as next resource user from ready-queue. (configuration of ready-queue and waiting-queue is shown in figure 14)
figure 14, blockEqPartition_p7.jpg
2nd time unit: SM0 computes index of hw1, then does read operation. Again hw1 goes to I/O wait and hw2 is next resource user.
….
22-th time unit: SM0 computes index of hw21, then do read operation
At this time, hw0 completes read operation and go back to ready-queue, but it locates behind hw31. Hence scheduler chooses hw22 as next resource user
(configuration of ready-queue and waiting-queue is shown in figure 15)
figure 15, blockEqPartition_p8.jpg
32-th time unit: SM computes index of hw31, then does read operation.
At this moment, ready-queue has hw0 ~ hw10 which are back from waiting-queue. Scheduler chooses hw0 as next resource user. Then process second tile.
(configuration of ready-queue and waiting-queue is shown in figure 16)
figure 16, blockEqPartition_p9.jpg
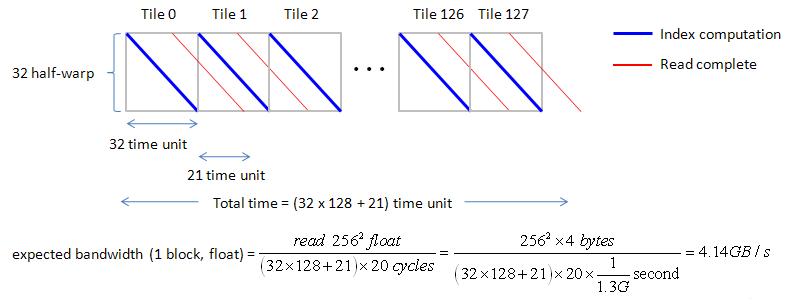
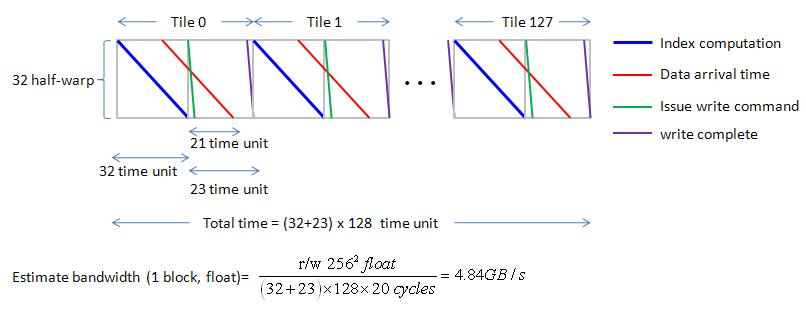
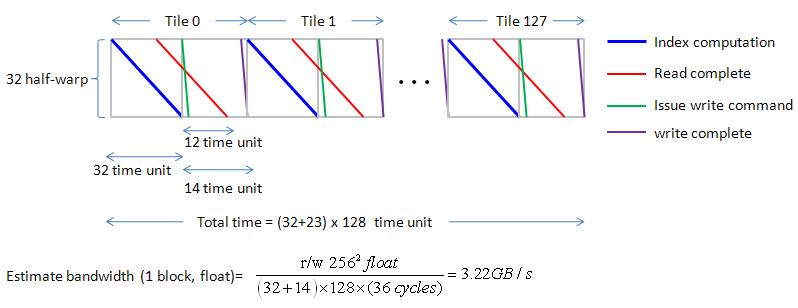
For n1 = n2 = 256, one tile of “float” has dimension 64x8 = 512, then there are 128 tiles, Gatt chart of 32 half-warp is shown in figure 17.
we can easily to estimate bandwidth by this regular Gatt chart, bandwidth is 4.14GB/s.
figure 17, blockEqPartition_p10.jpg
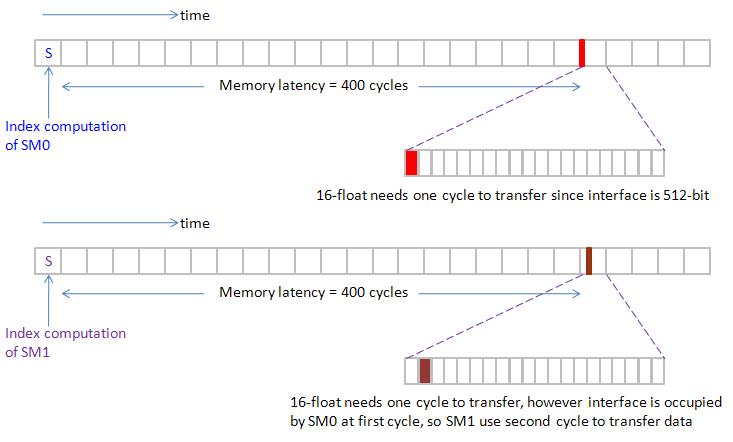
Case 2: type = double and NUM_PARTITION = 1, (only one SM executes 32 half-warp).
it has the same Gatt chart as case 1 except one transaction of double is 128 bytes which need two cycles to transfer through 512-bit interface. (see figure 18)
figure 18, blockEqPartition_p11.jpg
Case 3: type = float and NUM_PARTITION = 2, (two active SMs, each has one thread block)
two SMs run simultaneously and have the same time chart except data transfer since only one memory controller.
SM0 and SM1 issue read command at the same time, and two read requests target different partitions. Two partitions decode row address, column address and fetch data into buffer, however they share the same I/O bus. Suppose partition 0 transfer data first, then partition 1 can use I/O bus only when partition 0 has completed the transfer.
figure 19, blockEqPartition_p12.jpg
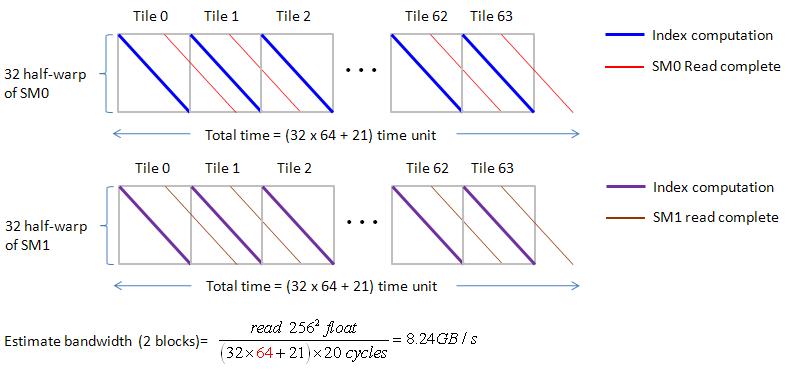
For n1 = n2 = 256, one tile of “float” is 64x8 = 512. when using two blocks (two active SMs, each has one block), then each SM deal with 64 tiles.
two SM has the same Gatt chart as that of NUM_PARTITION = 1 but only 64 tiles processed by each SM.
hence bandwidth is doubled, see figure 20.
figure 20, blockEqPartition_p13.jpg
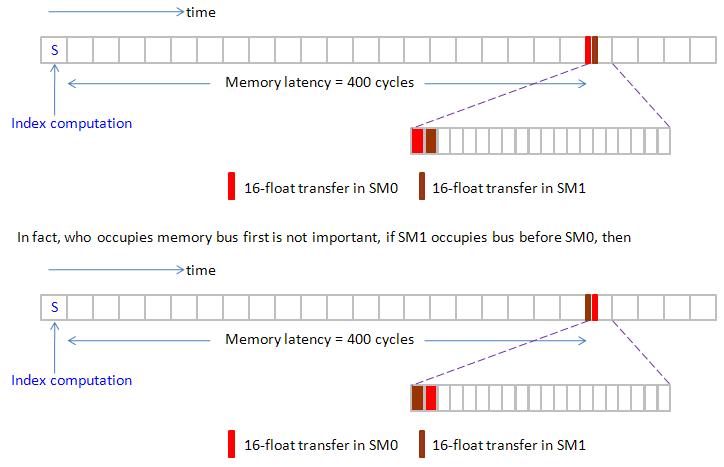
Another view: Since two SM are synchronous on index computation, all what we care about is timing sequence of “read operation”. Hence we can combine Gatt chart of two SM into one Gatt chart as you see figure 21. Moreover which SM occupies I/O bus first is not important.
figure 21, blockEqPartition_p14.jpg
Case 4: type = double and NUM_PARTITION = 2 (upper panel of figure 22)
Case 5: type = float and NUM_PARTITION = 4 (lower panel of figure 22)
figure 22, blockEqPartition_p15.jpg
Case 6: type = double and NUM_PARTITION = 4 (upper panel of figure 23)
Case 7: type = float and NUM_PARTITION = 8 (lower panel of figure 23)
figure 23, blockEqPartition_p16.jpg
Case 8: type = double and NUM_PARTITION = 8 (figure 24)
figure 24, blockEqPartition_p17.jpg
Observation: since “index computation” requires 20 cycles, it is larger than duration of 128-byte transfer of all eight partitions. Hence when number of active SM is doubled, then bandwidth is doubled.
Question: how about if we consider “write operation” after “read operation” ?
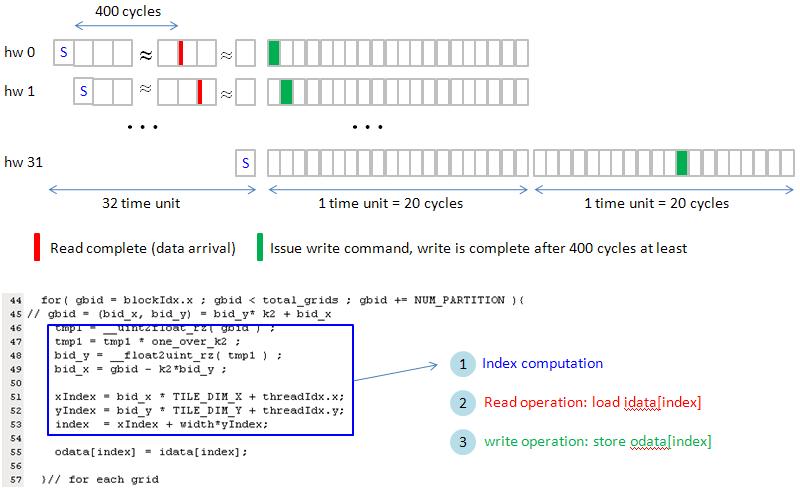
we need to issue "write operation" after read operation is done. Remember that we only one cycle to issue write command, not 20 cycles,
in figure 25, each half-warp issue write command one-by-one.
figure 25, blockEqPartition_p18.jpg
Combine timing sequence of (1) index computation (2) read complete (3) issue write command (4) write complete
figure 26, blockEqPartition_p19.jpg
Remark: from experiment data, bandwidth (1 block, float) is 3.1 GB/s, this is smaller than 4.84GB/s.
Hence memory latency may be larger than 400 cycles.
Conclusion: 16-double is 2 times the size of 16-float such that it requires 2 cycles to pass through 512-bit memory interface. However 16-double has benefit if burst of memory bus is regular under transfer of 16-float. In our “blockEqPartition" example, burst of memory bus is less than duration of index computation when NUM_PARTITION is less than 8. Hence bandwidth of 16-double is always twice than bandwidth of 16-float.
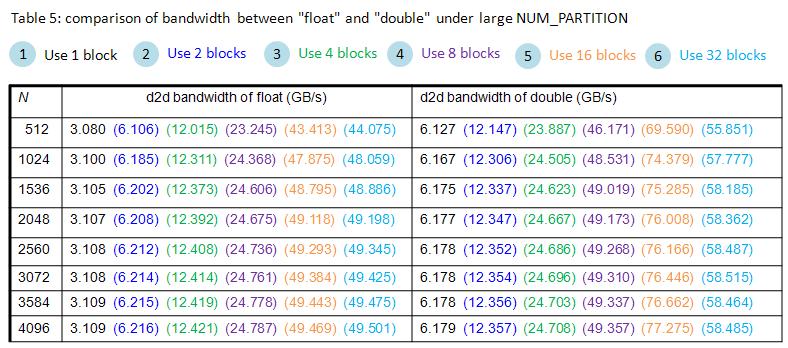
However this kind of analysis does not hold for large NUM_PARTITION = 32.
In Table 5, when NUM_PARTITION = 32, bandwidth of float does not increase whereas bandwidth of double decreases, this is very strange, I don’t have any idea to explain this.
Table 5, blockEqPartition_p20.jpg
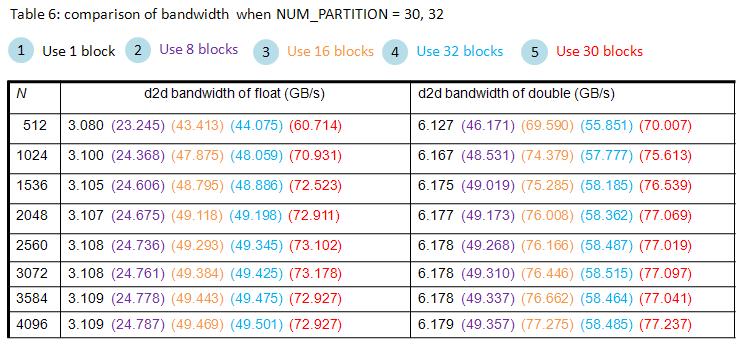
Question: we do extra experiment for NUM_PARTITION = 30, which is listed in table 6.
Amazingly, bandwidth of NUM_PARTITION = 30 is better than bandwidth of NUM_PARTITION = 32 and NUM_PARTITION = 16 , why?
Table 6, blockEqPartition_p21.jpg
Ans: recall a tile of “double” is 32 x 16, there are 8 x 16 = 128 tiles in 256x256 data, see figure 27.
figure 27, blockEqPartition_p22.jpg
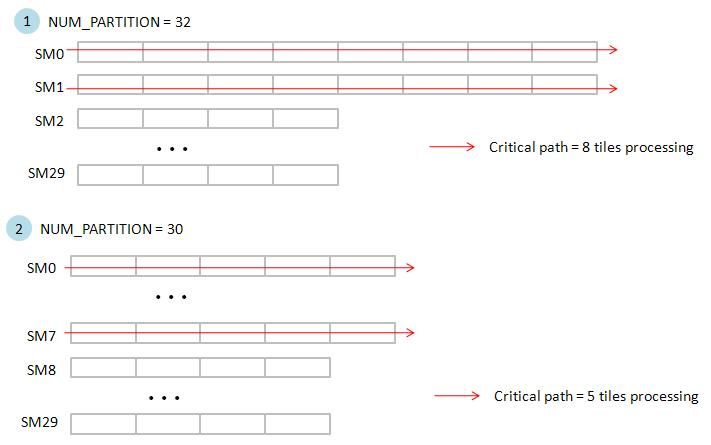
Case 1: NUM_PARTITION = 32
In our algorithm of "blockEqPartition", each thread block deals with 128/ NUM_PARTITION = 4 tiles.
However TeslaC1060 has only 30 SMs, this means that SM0 and SM1 contains two thread block and SM2 ~ SM29 contains one thread block.
This means that critical path is SM0 and SM1. see upper panel of figure 28.
Remark: each SM in TeslaC1060 has 1024 active
threads at most, and thread block contains 512 threads, so one SM can contains
two thread blocks
and 32 thread blocks can be assigned to 30 SMs such that SM0 and SM1 have two
thread blocks and SM2 ~ SM29 have one thread block.
case 2: NUM_PARTITION = 30
Each thread block deals with 128/ NUM_PARTITION = 4.2667 tiles.
this means that SM0 ~ SM7 contains 5 thread block and SM8 ~ SM29 contains 4 thread block. This means that critical path is SM0~ SM7.
see lower panel of figure 28.
figure 28, blockEqPartition_p23.jpg
Conclusion:
1. Critical path of NUM_PARTITION = 32 is 8 tiles whereas Critical path of NUM_PARTITION = 30 is 5 tiles, hence bandwidth of NUM_PARTITION = 30 is better than bandwidth of NUM_PARTITION = 32 .
2. Critical path of NUM_PARTITION = 16 is also 8 tiles, therefore
(1) For type = float, bandwidth of NUM_PARTITION = 32 is the same as bandwidth of NUM_PARTITION = 16
(2) For type = double, bandwidth of NUM_PARTITION = 32 is worse than bandwidth of NUM_PARTITION = 16, I still have no idea.
we make two mistakes,
first “index computation” costs 18.2 cycles, this is measured by 1 SM, say “index computation” of 1 SM needs 18.2 cycles. However one command of a half-warp needs two cycles since SM has only 8 SPs. Hence “index computation” of a half-warp needs 18.2 x 2 = 36.4 cycles. We need to modify assumption 1
Assumption 1: index computation requires 36 cycles for “float” and “double”
second, Data rate of memory bus in TeslaC1060 is 800MHz but core frequency is 1.3GHz , so 1 memory cycle = 1.664 core cycle.
For simplicity, we set 1 memory cycle = 2 core cycles such that assumption 2 is modified as
Assumption 2: memory latency is 400 cycles but 16-float can be transferred at 402-th cycle, 16-double can be transferred at 404-th cycle.
we combine assumption 1 and assumption 2 and set basic time unit as 36 cycles, then
1. Gatt chart of one half-warp is shown in figure 29.
figure 29, blockEqPartition_p24.jpg
2. partial Gatt chart of 32 half-warps in one SM is shown in figure 30 and complete Gatt chart is shown in figure 31.
we can estimate bandwidth in figure 31, it is 3.22 GB/s which is near experimental result, 3.1GB/s
figure 30, blockEqPartition_p25.jpg
figure 31, blockEqPartition_p26.jpg
New correction (209/10/17)
Sorry, 800MHz of TeslaC1060 is I/O bus rate, for data rate, we should multiply it by two, say 1600MHz since DDR.
However in order to match previous data, I would like to pull down the clock of DRAM to 400MHz such that data rate is 800MHz.
Next I want to argue that bandwidth of "double" is
better than bandwidth of "float" near maximum bandwidth.
We take 512 x 512 data as an example, one tile is composed of 512 data elements and one thread block (512 threads) deals with one tile.
This means that 512 x 512 data has 512 tiles to be processed.
Each thread block deals with 512/ NUM_PARTITION = 17.0667 tiles. For simplicity we assume that each thread block deals with 17 tiles.
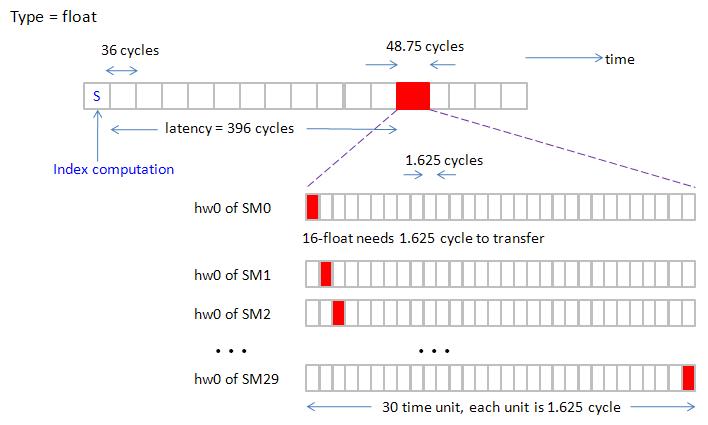
Recall one 512-bit transfer needs 1.625 core cycle under data rate is 800MHz and core frequency is 1.3GHz.
Then the duration that 30 SM transfer 512-bit (16-floats) simultaneously is 1.625 x 30 = 48.75 core cycles.
Here we assume 30 SM transfer 16-float back to back without any vacuum.
Similarly the duration that 30 SM transfer 16-double simultaneously is (1.625 x 2) x 30 = 97.5 core cycles.
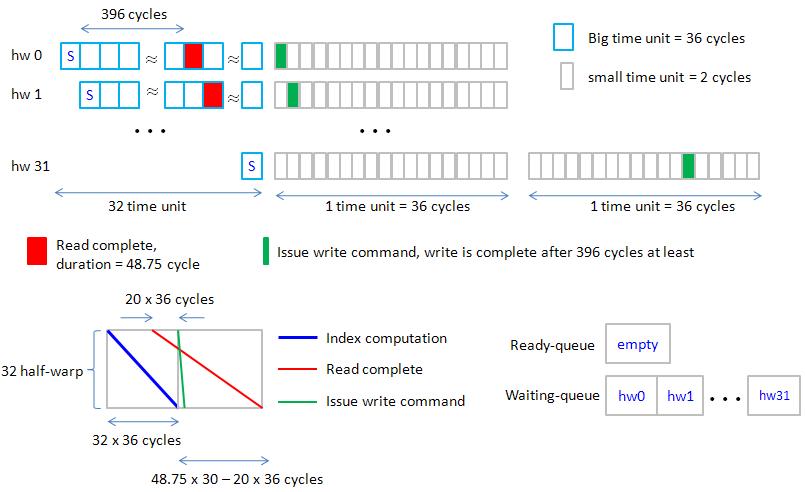
Let us consider type = float, combine Gatt chart (index computation + read operation) of hw0 (half-warp 0) of 30 SMs in figure 32.
Note that 30 SMs transfer 16-float back to back such that duration of transferring 16-float of 30 SM is 48.75 core cycle.
Moreover “index computation” of half-warp is only 18 x 2 = 16 core cycle.
So overhead of “index computation” is less than overhead of transferring 16-float of 30 SM.
figure 32, blockEqPartition_p27.jpg
Then Combine (1) index computation (2) read command (3) read complete (4) write command, see figure 33
figure 33, blockEqPartition_p28.jpg
note that when 30 SM issue write command, they are moved to waiting-queue, at this time, 30 SM are idle.
Therefore it is simple to combine write operation, see figure 34.
figure 34, blockEqPartition_p29.jpg
note that hw0 moves to ready-queue after write operation is complete, so hw0 can do "index computation" at next time unit.
That's why blue rectangle follows purple rectangle in figure 34.
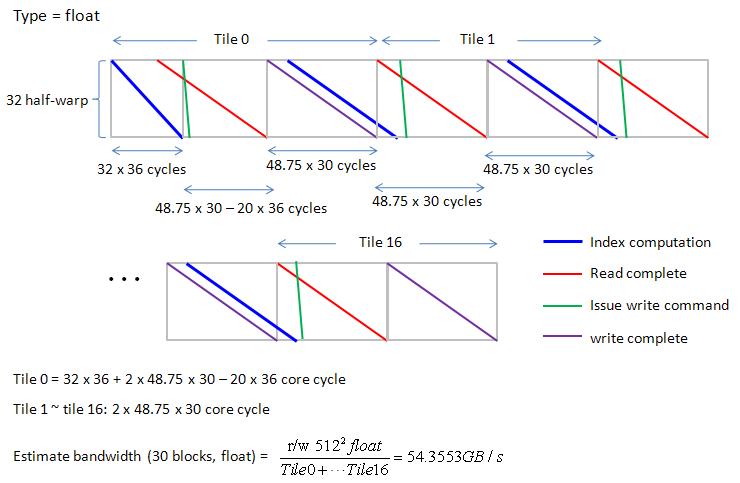
Finally we combine Gatt chart of 17 tiles in figure 35,
Tile 0 = 32 x 36 + 2 x 48.75 x 30 – 20 x 36 core cycle
Tile 1 ~ tile 16: 2 x 48.75 x 30 core cycle
then bandwidth is 54.3553 GB/s (this number is only half of maximum bandwidth of Tesla C1060 since we pull down I/O rate of GDDR3)
figure 35, blockEqPartition_p30.jpg
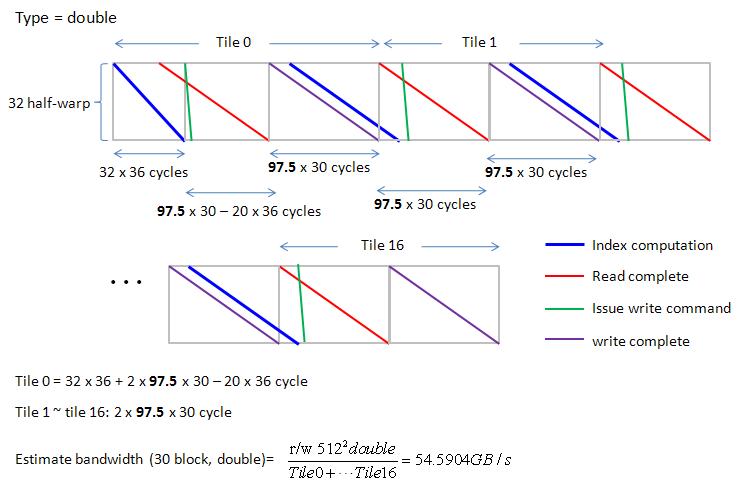
Similarly Gatt chart of “double” is the same as “float” except memory latency (replace 48.75 cycle by 97.5 cycle), see figure 36.
bandwidth is 54.5904 GB/s, slightly larger than bandwidth of "float".
figure 36, blockEqPartition_p31.jpg
Formally speaking, if we define four quantities as
(1) halfwarpPerBlock = 32
(2) Index_computation = 36 core cycle
(3) Latency = 48.75 core cycle (type = float ) or 97.5 core cycle (type = double)
(4 )numberSM = 30
then we have the same formula of total time on type = float and type = double
Total time = (halfwarpPerBlock – 20) x Index_computation + 17 x 2 x Latency x numberSM, unit = core cycles.
However if we extract parameters further, and define
(4) X = (halfwarpPerBlock – 20) x Index_computation
(5) Y = 17 x 2 x Latency (type = float) x numberSM
then
bandwidth (float) = 512^2 * sizeof(float) * 2 / (X+Y) and
bandwidth (double) = 512^2 * sizeof(double) * 2 / (X+2Y) .
Hence bandwidth (double) /bandwidth (float) = 1 + X/(X+2Y) > 1.
Conclusion: if overhead of "transfer 16-float of 30 SM" is larger than overhead of "index computation", then
transfer of "double" is better than transfer of "float".
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}